Introduction
In MarkLogic, forests lay at the interface between the logical and physical handling of data. When you look at your dataset, you think of the documents being part of a database; this is the logical view. The way this works, especially on a cluster with several hosts, depends entirely on the forests, which store documents and perform queries on their "own subset of the whole database;" this is the physical view.
In order to achieve high-availability, forests can be replicated (the whole story is much richer, but this is a useful simplification.) The concept is dead simple: have another forest, within which you cannot insert documents yourself, but which is rather linked to the main forest and replicate every bit of change that happens. This replication happens synchronously and transactionally: when a transaction is committed, you can be sure its changes are reflected in the main forests and all their replicas, if any.
But how to define the forests? How many? On which host? What about the replicas?
This article addresses these questions, as well as how they apply, or not, to the
default databases (like Meters and Security.)
Note that I am not going to address the differences between E-nodes and D-nodes in this article, nor why and when it is a good idea to have dedicated E-nodes and D-nodes. I assume every host in the cluster is a D-node, but if it is not the case with your cluster, for any reason, just read "cluster" hereafter as meaning "the subset of the cluster comprised of its D-nodes only." If you are not sure what E-nodes and D-nodes are, you can safely ignore this paragraph, as far as this article is concerned.
I am not discussing details of how to set up a particular forest layout either.
This article addresses the "theory," how to define a forest layout, but not how to
materialize this forest layout on one cluster. Amongst other options, you can
achieve it by hand using the Admin
Console, by writing scripts using the Manage API, or by using features of
ML Gradle dedicated to configuring forest topologies
(e.g. mlDatabasesWithForestsOnOneHost, mlContentForestsPerHost,
mlForestsPerHost, and mlDatabaseNamesAndReplicaCounts.) Use your
tool of choice.
TL;DR Go straight to the last section for a summary of the recommendations. Although to understand the rationale behind them, you will need to read the full article.
I want to thank Mads Hansen and Brent Hartwig for their useful (as always) feedback on this article!
A database categorization
In a MarkLogic cluster, databases are not all equivalent. They have different functions, different roles, and this has an impact on how we define the forests and their replicas. This is my own terminology, in order to apply different replication policies to different kinds of database.
The most important type of database is what I call "content databases." If you use DHF, this is your "FINAL" database. And sometimes your "STAGING" database as well, depending on the nature of the documents you store in it (STAGING should not be crucial for your business to operate, but sometimes is.) More generally, it is the databases you use to store your actual data, those that typically grow large.
A second type of database is the "utility databases." This encompasses modules, triggers, schemas databases. These databases typically do not grow large. They usually contain manually crafted development artefacts (XQuery or JavaScript code, XML schemas, TDE templates, etc.) Any database depends on a security database, and optionally on a schema and a triggers database; if any of the databases it depends on is unavailable, then it becomes itself unavailable. Any app server depends on a content database, and optionally on a modules and a last-login database; similarly, if any of the databases it depends on is unavailable, then it becomes itself unavailable.
Finally, we have more specific databases, namely "Security," "Meters," and "App-Services." Let us call them "system databases."
Content databases
For content databases, we want to spread out the documents over the entire cluster (to be more precise, over the D-nodes of the cluster.) This ensures that the storage is balanced across the cluster, but also that the processing related to the data is also balanced across the cluster. When executing a query to, say, retrieve all documents containing the word "MarkLogic," each forest of the targeted database assembles a list of all the documents it contains that match the query. The E-node (executing the query) then combines the result.
We are not dealing here with the details of how many forests to create per host for a content database (it is typical to have 2, 3, or 4, but it all depends on your dataset and your machine configuration.) It is important though to understand how to balance them over the cluster. A typical way is to have the same number of forests on each host, to name them using a suffix "-1", "-2", etc., to assign the first one on the first host (A), the second one on host B, and so on, then "cycle" back to A when we went to the entire cluster. If we look at an example with a cluster of 3 nodes, each of them with 2 forests:
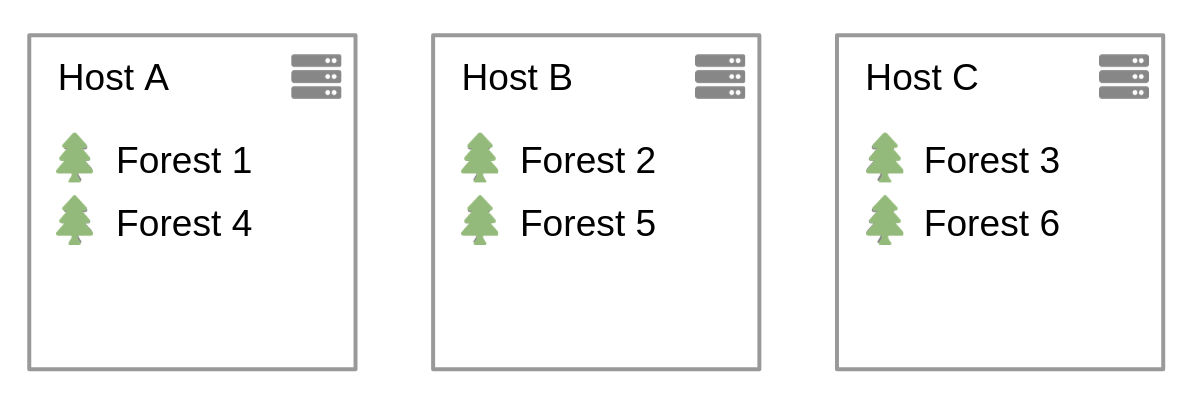
For the replicas, the rule of thumb is that you want 1 replica per main forest. The naming convention is to name them from the main forest, adding "-replica", "replica-1", or "-r". To assign them to host, take the main forest from host A (here forests 1 and 4), assign the first one to the next host, then the next one, etc. So forest 1-r goes to B, and 4-r to C. And you repeat for each host. Given the previous example, this gives us:
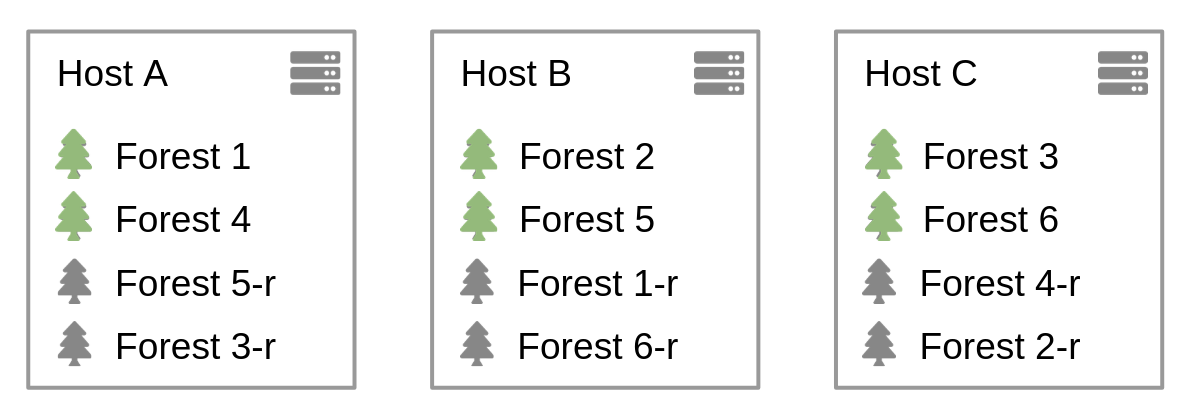
Using this repartition, if we lose, say, host B, both forests 2 and 5 become unavailable. But their respective replicas take over, 2-r and 5-r. Because they are each on a different host (A and C,) the extra load is balanced between the 2 remaining hosts. It is important to ensure that both 2-r and 5-r are not on the same host, to avoid that a single host inherits the entire extra load of losing B:
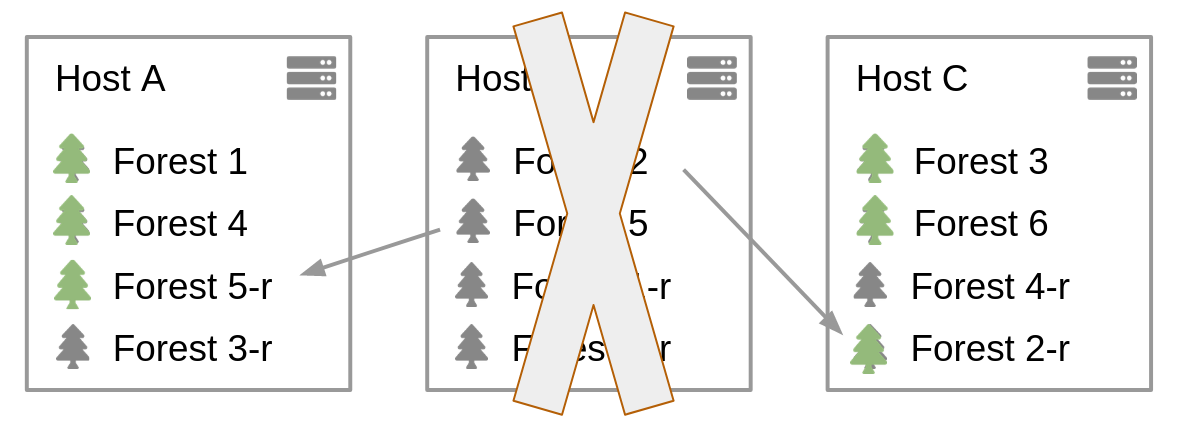
Whilst I am not diving into the details of how many forests to create per host for a content database, it is worth to remind you here that the storage footprint of a forest should never be above 400GB. There are many other factors that could impact the number of forests, but this rule is easy to check and apply, and should always be followed.
Replicas
When a forest is not available, the database it is attached to becomes unavailable as well. This can happen for instance because the host the forest is hosted on is lost, or the disk it is stored on has a problem. Unless the forest has one replica still available. In which case the replica takes over, and becomes the "acting master."
Something to understand, when such a switch to replicas occurs, is that it does not switch back automatically when the host is back. MarkLogic does not make any assumption that the root cause of the switch to replicas has been fixed. So you have to explicitly switch them back to normal when you know that the cause is fixed, and you are ready to do so.
In order to switch back to the "usual" master, when a replica is "acting master," you need to restart the replica. Since the replica restarts, it is not available for a short period of time, therefore the "usual" master (which is now "acting replica") takes over and becomes the master. You can restart a forest from the Admin Console: go to the forest page, tab "Status," then click on "restart":
Do not forget: restart the replica forest, the one acting as master!
As explained in the database categorization, if a database that another database or app server depends on becomes unavailable, then the latter also becomes unavailable. So if you add replicas to the forests of a content database, it is important to add them to its security, schemas, and triggers databases as well. If you do not, as soon as any forest of these dependent-on databases is lost, the content database itself becomes unavailable, regardless of the replicas of its own forests. Similarly, if an app server is connected to that database as its content database, you want to add replicas to the forest of its modules database, or the app server will be unavailable as soon as the modules forest will be lost.
The rule of thumb for deciding the number of replica forest to add to a master forest is simple: one.
Utility databases
For utility databases, the situation is different. Typically, these databases contain few documents: modules, schemas, triggers, it rarely grows above a few thousands documents, at most.
Security databases also fall into this category. Except for the database named "Security," which is used by the Admin Console, see next section (as it is used to access the Admin Console, we want to give it more care.) It is usual for all databases on a cluster to use a single one security database: "Security." If you use your own, project-specific security databases, they should be treated like any other utility database.
The most efficient layout for the forests of utility databases is to have a single one forest, and for that forest to have one replica. The overhead of having several forests, and maintaining them, does not bring any value. It is simpler to have them all on the same host, but you can spread them across the cluster if you prefer. The point is to have a single forest for utility databases.
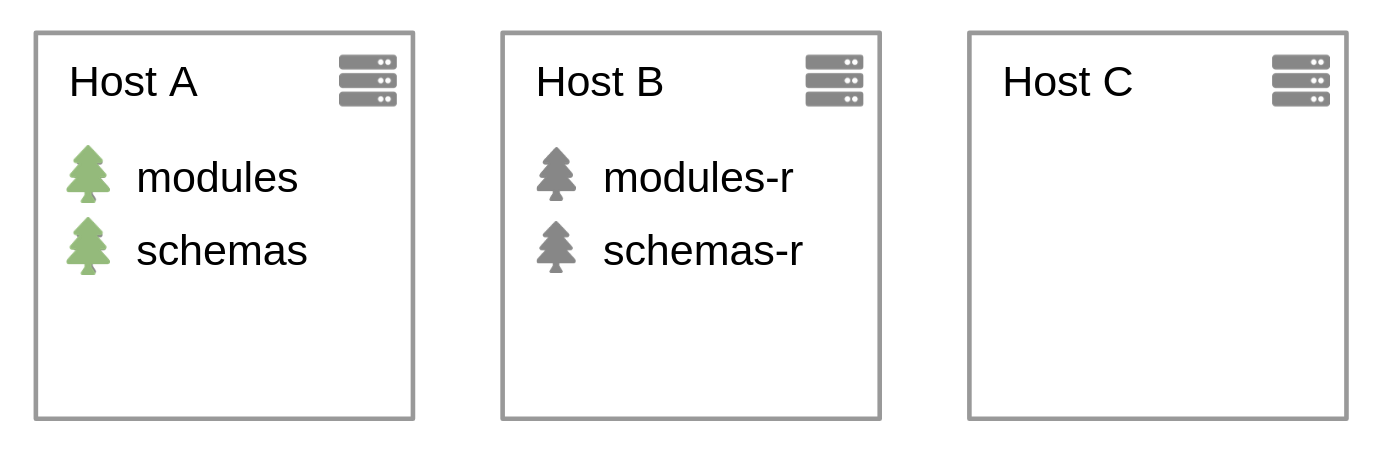
If you use the "last login" option on an app server, which attaches a database to record the last login information, you should apply the same strategy: 1 forest + 1 replica.
System databases
On a cluster, 3 databases have a special function, although they work like any other database. The "Security" database is used to store the security-related data on the cluster, like users and roles, and in particular users and credentials to connect to the Admin Console and QConsole. The "Meters" database is used to capture metrics about the cluster, its various components, and resource consumption (I/O, CPU, number of fragments, memory, etc.) The "App-Services" is used to store information for applications, mainly workspaces and query history for QConsole. Given the special role of these databases, let us look in detail whether we want to give them extra care.
First, a quick reminder about what happens when a host is lost on a cluster. On a MarkLogic cluster, there is constant messaging between the hosts: the heartbeat. When a host does not reply anymore, it is considered unavailable, and the rest of the cluster continues without it. If it contains any forest, their replicas switch to acting master, and for forests with no replica available, they are turned offline, making its database unavailable as well. For a cluster to keep operating, it needs to contain an absolute majority of hosts (strictly over 50%.) This guarantees that there is only one cluster operating, and that we never end up with two "residual" clusters operating at the same time.
"Security" database. A content database can use a specific security database, not necessarily the out-of-the-box database named "Security." For such security databases, you want to apply the same rules as for utility databases: volume of data is small, and the content database is resilient to losing as many hosts for its security database forests than for its own forests. Here, we are considering only the database named "Security," used among other things to access the Admin Console on port 8001.
Since the "Security" database is used to access the Admin Console (and is usually the security database of all databases on the cluster as well,) we want it to be replicated. Use the same rule as for utility databases: 1 forest + 1 replica.
"App-Services" database. It is used by QConsole to store queries. It is also the content database associated to both app servers "Manage" (port 8002) and "HealthCheck" (port 7997.) As such, you probably want it replicated as well. Once again, use the same rule as for utility databases: 1 forest + 1 replica.
Note that the "App-Services" app server (bound to port 8000, providing QConsole as well as the default REST instance) is bound by default to "Modules" as its modules database, and to "Documents" as its content database. Unless you use this (if you do, you know,) you can change its modules database to "(file system)" and its content database to "App-Services" in order to reduce its dependencies (its URL rewriter bounds it to "App-Services", so you cannot get rid of this one.) If you do not, QConsole will not be available if either of the "Modules" or the "Documents" forests is lost.
"Meters" database. It is used by the cluster to store the metrics MarkLogic automatically captures. This is the data available as diagrams on the Monitoring History application on port 8002. By default, MarkLogic captures metrics every minute, and keep them for 7 days (this is called "raw" data.) It also aggregates the raw data into hourly metrics, and keeps them for 30 days. Finally, it aggregates daily metrics, and keeps them for 90 days.
If the "Meters" database is not available, for instance if one of its forest is not available, the metrics data cannot be used, and cannot be captured either during that time. So it is up to you to decide whether being able to access and/or capture metrics data is important, even if the host containing its forest is lost. My rule of thumb is to have the "Meters" forest replicated.
As per the number of forests, it depends on the volume. "Meters" is usually much bigger than utility databases, but still manageable for one single forest. So in doubt, keep a single one forest (with a replica,) and keep an eye on its size over time.
Change layout
As the project evolves, and more data is ingested into the database, it is likely that you will need more forests on the content databases. Either on existing hosts, or on new hosts that you add to the cluster. In both cases, you have to adapt your forest layout. Since you cannot easily move forests across hosts on an existing, live environment, this requires to be planned properly. Hopefully, this will be the topic of a subsequent article, detailing a few tips and best practices to do so.
Summary
Dispatching the forests properly over the cluster is important to balance the load over the hosts. Correctly dispatching their replicas is paramount to ensuring high availability (HA) and being resilient in case of an incident on a host. In case of such an incident, it is at least as important to make sure that the resulting, weakened cluster is itself well balanced.
The following table is a summary of the recommendations detailed above. Refer to the entire article for more explanations (the type of databases is detailed at the beginning of the article).
| Forests | Replicas | Notes | |
|---|---|---|---|
| Content database | several per host | 1 per master | make sure that each host has the same number of forests, the same number of replicas, and that losing one host will result in a balanced extra load over the other hosts, through the corresponding replicas |
| Utility database | 1 single forest | 1 single replica | |
| Security | 1 single forest | 1 single replica | |
| App-Services | 1 single forest | 1 single replica | |
| Meters | 1 single forest | 1 single replica | keep an eye on the forest volume, in order to split it if necessary; you may also want to have no replica, depending on the importance you give to having metrics available and/or captured in a degraded cluster |
These are best practices, rules of thumb, make sure to adapt them to your specific needs. The most important thing to take from this article is that the forest layout matters, it is important. Make sure to define it properly, to document it clearly, and to test the various incident scenarii.
Posted by Florent Georges, on 2023-08-06T15:54:45, tags: forest, high-availability and marklogic.